Unix的缺陷

我想通过这篇文章解释一下我对 Unix 哲学本质的理解。我虽然指出 Unix 的一个设计问题,但目的并不是打击人们对 Unix 的兴趣。虽然 Unix 在基础概念上有一个挺严重的问题,但是经过多年的发展之后,这个问题恐怕已经被各种别的因素所弥补(比如大量的人力)。但是如果开始正视这个问题,我们也许就可以缓慢的改善系统的结构,从而使得它用起来更加高效,方便和安全,那又未尝不可。同时也希望这里对 Unix 命令本质的阐述能帮助人迅速的掌握 Unix,灵活的应用它的潜力,避免它的缺点。
通常所说的“Unix哲学”包括以下三条原则[Mcllroy]:
- 一个程序只做一件事情,并且把它做好。
- 程序之间能够协同工作。
- 程序处理文本流,因为它是一个通用的接口。
这三条原则当中,前两条其实早于 Unix 就已经存在,它们描述的其实是程序设计最基本的原则 —— 模块化原则。任何一个具有函数和调用的程序语言都具有这两条原则。简言之,第一条针对函数,第二条针对调用。所谓“程序”,其实是一个叫 "main" 的函数(详见下文)。
所以只有第三条(用文本流做接口)是 Unix 所特有的。下文的“Unix哲学”如果不加修饰,就特指这第三条原则。但是许多的事实已经显示出,这第三条原则其实包含了实质性的错误。它不但一直在给我们制造无需有的问题,并且在很大程度上破坏前两条原则的实施。然而,这条原则却被很多人奉为神圣。许多程序员在他们自己的程序和协议里大量的使用文本流来表示数据,引发了各种头痛的问题,却对此视而不见。
Linux 有它优于 Unix 的革新之处,但是我们必须看到,它其实还是继承了 Unix 的这条哲学。Linux 系统的命令行,配置文件,各种工具之间都通过非标准化的文本流传递数据。这造成了信息格式的不一致和程序间协作的困难。然而,我这样说并不等于 Windows 或者 Mac 就做得好很多,虽然它们对此有所改进。实际上,几乎所有常见的操作系统都受到 Unix 哲学潜移默化的影响,以至于它们身上或多或少都存在它的阴影。
Unix 哲学的影响是多方面的。从命令行到程序语言,到数据库,Web…… 计算机和网络系统的方方面面无不显示出它的影子。在这里,我会把众多的问题与它们的根源 —— Unix哲学相关联。现在我就从最简单的命令行开始吧,希望你能从这些最简单例子里看到 Unix 执行命令的过程,以及其中存在的问题。(文本流的实质就是字符串,所以在下文里这两个名词通用)
一个 Linux 命令运行的基本过程
几乎每个 Linux 用户都为它的命令行困惑过。很多人(包括我在内)用了好几年 Linux 也没有完全的掌握命令行的用法。虽然看文档看书以为都看透了,到时候还是会出现莫名其妙的问题,有时甚至会耗费大半天的时间在上面。其实如果看透了命令行的本质,你就会发现很多问题其实不是用户的错。Linux 遗传了 Unix 的“哲学”,用文本流来表示数据和参数,才导致了命令行难学难用。
我们首先来分析一下 Linux 命令行的工作原理吧。下图是一个很简单的 Linux 命令运行的过程。当然这不是全过程,但是更具体的细节跟我现在要说的主题无关。
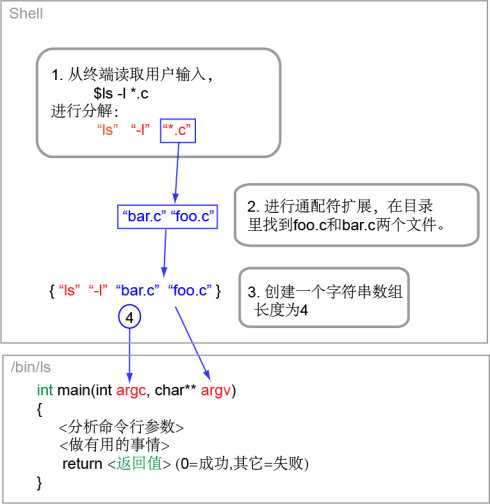
从上图我们可以看到,在 ls 命令运行的整个过程中,发生了如下的事情:
- shell(在这个例子里是bash)从终端得到输入的字符串 "ls -l *.c"。然后 shell 以空白字符为界,切分这个字符串,得到 "ls", "-l" 和 "*.c" 三个字符串。
- shell 发现第二个字符串是通配符 "*.c",于是在当前目录下寻找与这个通配符匹配的文件。它找到两个文件: foo.c 和 bar.c。
- shell 把这两个文件的名字和其余的字符串一起做成一个字符串数组 {"ls", "-l", "bar.c", "foo.c"}. 它的长度是 4.
- shell 生成一个新的进程,在里面执行一个名叫 "ls" 的程序,并且把字符串数组 {"ls", "-l", "bar.c", "foo.c"}和它的长度4,作为ls的main函数的参数。main函数是C语言程序的“入口”,这个你可能已经知道。
- ls 程序启动并且得到的这两个参数(argv,argc)后,对它们做一些分析,提取其中的有用信息。比如 ls 发现字符串数组 argv 的第二个元素 "-l" 以 "-" 开头,就知道那是一个选项 —— 用户想列出文件详细的信息,于是它设置一个布尔变量表示这个信息,以便以后决定输出文件信息的格式。
- ls 列出 foo.c 和 bar.c 两个文件的“长格式”信息之后退出。以整数0作为返回值。
- shell 得知 ls 已经退出,返回值是 0。在 shell 看来,0 表示成功,而其它值(不管正数负数)都表示失败。于是 shell 知道 ls 运行成功了。由于没有别的命令需要运行,shell 向屏幕打印出提示符,开始等待新的终端输入……
从上面的命令运行的过程中,我们可以看到文本流(字符串)在命令行中的普遍存在:
- 用户在终端输入是字符串。
- shell 从终端得到的是字符串,分解之后得到 3 个字符串,展开通配符后得到 4 个字符串。
- ls 程序从参数得到那 4 个字符串,看到字符串 "-l" 的时候,就决定使用长格式进行输出。
接下来你会看到这样的做法引起的问题。
冰山一角
在《Unix 痛恨者手册》(The Unix-Hater's Handbook, 以下简称 UHH)这本书开头,作者列举了 Unix 命令行用户界面的一系列罪状,咋一看还以为是脾气不好的初学者在谩骂。可是仔细看看,你会发现虽然态度不好,他们某些人的话里面有非常深刻的道理。我们总是可以从骂我们的人身上学到一些东西,所以仔细看了一下,发现其实这些命令行问题的根源就是“Unix 哲学” —— 用文本流(字符串)来表示参数和数据。很多人都没有意识到,文本流的过度使用,引发了太多问题。我会在后面列出这些问题,不过我现在先举一些最简单的例子来解释一下这个问题的本质,你现在就可以自己动手试一下。
- 在你的 Linux 终端里执行如下命令(依次输入:大于号,减号,小写字母l)。这会在目录下建立一个叫 "-l" 的文件。
$ >-l
- 执行命令 ls * (你的意图是以短格式列出目录下的所有文件)。
你看到什么了呢?你没有给 ls 任何选项,文件却出人意料的以“长格式”列了出来,而这个列表里面却没有你刚刚建立的那个名叫 "-l" 的文件。比如我得到如下输出:
-rw-r--r-- 1 wy wy 0 2011-05-22 23:03 bar.c-rw-r--r-- 1 wy wy 0 2011-05-22 23:03 foo.c
到底发生了什么呢?重温一下上面的示意图吧,特别注意第二步。原来 shell 在调用 ls 之前,把通配符 * 展开成了目录下的所有文件,那就是 "foo.c", "bar.c", 和一个名叫 "-l" 的文件。它把这 3 个字符串加上 ls 自己的名字,放进一个字符串数组 {"ls", "bar.c", "foo.c", "-l"},交给 ls。接下来发生的是,ls 拿到这个字符串数组,发现里面有个字符串是 "-l",就以为那是一个选项:用户想用“长格式”输出文件信息。因为 "-l" 被认为是选项,就没有被列出来。于是我就得到上面的结果:长格式,还少了一个文件!
这说明了什么问题呢?是用户的错吗?高手们也许会笑,怎么有人会这么傻,在目录里建立一个叫 "-l" 的文件。但是就是这样的态度,导致了我们对错误视而不见,甚至让它发扬光大。其实撇除心里的优越感,从理性的观点看一看,我们就发现这一切都是系统设计的问题,而不是用户的错误。如果用户要上法庭状告 Linux,他可以这样写:
起诉状
原告:用户 luser
被告:Linux 操作系统
事由:合同纠纷
- 被告的文件系统给用户提供了机制建立这样一个叫 "-l" 的文件,这表示原告有权使用这个文件名。
- 既然 "-l" 是一个合法的文件名,而 "*" 通配符表示匹配“任何文件”,那么在原告使用 "ls *" 命令的时候,被告就应该像原告所期望的那样,以正常的方式列出目录下所有的文件,包括 "-l" 在内。
- 但是实际上原告没有达到他认为理所当然的结果。"-l" 被 ls 命令认为是一个命令行选项,而不是一个文件。
- 原告认为自己的合法权益受到侵犯。
我觉得为了免去责任,一个系统必须提供切实的保障措施,而不只是口头上的约定来要求用户“小心”。就像如果你在街上挖个大洞施工,必须放上路障和警示灯。你不能只插一面小旗子在那里,用一行小字写着: “前方施工,后果自负。”我想每一个正常人都会判定是施工者的错误。
可是 Unix 对于它的用户却一直是像这样的施工者,它要求用户:“仔细看 man page,否则后果自负。”其实不是用户想偷懒,而是这些条款太多,根本没有人能记得住。而且没被咬过之前,谁会去看那些偏僻的内容啊。但是一被咬,就后悔都来不及。完成一个简单的任务都需要知道这么多可能的陷阱,那更加复杂的任务可怎么办。其实 Unix 的这些小问题累加起来,不知道让人耗费了多少宝贵的时间。
如果你想更加确信这个问题的危险性,可以试试如下的做法。在这之前,请新建一个测试用的目录,以免丢失你的文件!
- 在新目录里,我们首先建立两个文件夹 dir-a, dir-b 和三个普通文件 file1,file2 和 "-rf"。然后我们运行 "rm *",意图是删除所有普通文件,而不删掉目录。
$ mkdir dir-a dir-b
$ touch file1 file2
$ > -rf
$ rm *
- 然后用 ls 查看目录。
你会发现最后只剩下一个文件: "-rf"。本来 "rm *" 只能删除普通文件,现在由于目录里存在一个叫 "-rf" 的文件。rm 以为那是叫它进行强制递归删除的选项,所以它把目录里所有的文件连同目录全都删掉了(除了 "-rf")。
表面解决方案
难道这说明我们应该禁止任何以 "-" 开头的文件名的存在,因为这样会让程序分不清选项和文件名?可是不幸的是,由于 Unix 给程序员的“灵活性”,并不是每个程序都认为以 "-" 开头的参数是选项。比如,Linux 下的 tar,ps 等命令就是例外。所以这个方案不大可行。
从上面的例子我们可以看出,问题的来源似乎是因为 ls 根本不知道通配符 * 的存在。是 shell 把通配符展开以后给 ls。其实 ls 得到的是文件名和选项混合在一起的字符串数组。所以 UHH 的作者提出的一个看法:“shell 根本不应该展开通配符。通配符应该直接被送给程序,由程序自己调用一个库函数来展开。”
这个方案确实可行:如果 shell 把通配符直接给 ls,那么 ls 会只看到 "*" 一个参数。它会调用库函数在文件系统里去寻找当前目录下的所有文件,它会很清楚的知道 "-l" 是一个文件,而不是一个选项,因为它根本没有从 shell 那里得到任何选项(它只得到一个参数:"*")。所以问题貌似就解决了。
但是这样每一个命令都自己检查通配符的存在,然后去调用库函数来解释它,大大增加了程序员的工作量和出错的概率。况且 shell 不但展开通配符,还有环境变量,花括号展开,~展开,命令替换,算术运算展开…… 这些让每个程序都自己去做?这恰恰违反了第一条 Unix 哲学 —— 模块化原则。而且这个方法并不是一劳永逸的,它只能解决这一个问题。我们还将遇到文本流引起的更多的问题,它们没法用这个方法解决。下面就是一个这样的例子。
冰山又一角
这些看似微不足道的问题里面其实包含了 Unix 本质的问题。如果不能正确认识到它,我们跳出了一个问题,还会进入另一个。我讲一个自己的亲身经历吧。我前年夏天在 Google 实习快结束的时候发生了这样一件事情……
由于我的项目对一个开源项目的依赖关系,我必须在 Google 的 Perforce 代码库中提交这个开源项目的所有文件。这个开源项目里面有 9000 多个文件,而 Perforce 是如此之慢,在提交进行到一个小时的时候,突然报错退出了,说有两个文件找不到。又试了两次(顺便出去喝了咖啡,打了台球),还是失败,这样一天就快过去了。于是我搜索了一下这两个文件,确实不存在。怎么会呢?我是用公司手册上的命令行把项目的文件导入到 Perforce 的呀,怎么会无中生有?这条命令是这样:
find -name *.java -print | xargs p4 add
它的工作原理是,find 命令在目录树下找到所有的以 ".java" 结尾的文件,把它们用空格符隔开做成一个字符串,然后交给 xargs。之后 xargs 以空格符把这个字符串拆开成多个字符串,放在 "p4 add" 后面,组合成一条命令,然后执行它。基本上你可以把 find 想象成 Lisp 里的 "filter",而 xargs 就是 "map"。所以这条命令转换成 Lisp 样式的伪码就是:
(map (lambda (x) (p4 add x))
(filter (lambda (x) (regexp-match "*.java" x))
(files-in-current-dir)))
问题出在哪里呢?经过一下午的困惑之后我终于发现,原来这个开源项目里某个目录下,有一个叫做 "App Launcher.java" 的文件。由于它的名字里面含有一个空格,被 xargs 拆开成了两个字符串: "App" 和 "Launcher.java"。当然这两个文件都不存在了!所以 Perforce 在提交的时候抱怨找不到它们。我告诉组里的负责人这个发现后,他说:“这些家伙,怎么能给 Java 程序起这样一个名字?也太菜了吧!”
但是我却不认为是这个开源项目的程序员的错误,这其实显示了 Unix 的问题。这个问题的根源是因为 Unix 的命令 (find, xargs) 把文件名以字符串的形式传递,它们默认的“协议”是“以空格符隔开文件名”。而这个项目里恰恰有一个文件的名字里面有空格符,所以导致了歧义的产生。该怪谁呢?既然 Linux 允许文件名里面有空格,那么用户就有权使用这个功能。到头来因此出了问题,用户却被叫做菜鸟,为什么自己不小心,不看 man page。
后来我仔细看了一下 find 和 xargs 的 man page,发现其实它们的设计者其实已经意识到这个问题。所以 find 和 xargs 各有一个选项:"-print0" 和 "-0"。它们可以让 find 和 xargs 不用空格符,而用 "NULL"(ASCII字符 0)作为文件名的分隔符,这样就可以避免文件名里有空格导致的问题。可是,似乎每次遇到这样的问题总是过后方知。难道用户真的需要知道这么多,小心翼翼,才能有效的使用 Unix 吗?
文本流不是可靠的接口
这些例子其实从不同的侧面显示了同一个本质的问题:用文本流来传递数据有严重的问题。是的,文本流是一个“通用”的接口,但是它却不是一个“可靠”或者“方便”的接口。Unix 命令的工作原理基本是这样:
- 从标准输入得到文本流,处理,向标准输出打印文本流。
- 程序之间用管道进行通信,让文本流可以在程序间传递。
这其中主要有两个过程:
- 程序向标准输出“打印”的时候,数据被转换成文本。这是一个编码过程。
- 文本通过管道(或者文件)进入另一个程序,这个程序需要从文本里面提取它需要的信息。这是一个解码过程。
编码的貌似很简单,你只需要随便设计一个“语法”,比如“用空格隔开”,就能输出了。可是编码的设计远远不是想象的那么容易。要是编码格式没有设计好,解码的人就麻烦了,轻则需要正则表达式才能提取出文本里的信息,遇到复杂一点的编码(比如程序文本),就得用 parser。最严重的问题是,由于鼓励使用文本流,很多程序员很随意的设计他们的编码方式而不经过严密思考。这就造成了 Unix 的几乎每个程序都有各自不同的输出格式,使得解码成为非常头痛的问题,经常出现歧义和混淆。
上面 find/xargs 的问题就是因为 find 编码的分隔符(空格)和文件名里可能存在的空格相混淆 —— 此空格非彼空格也。而之前的 ls 和 rm 的问题就是因为 shell 把文件名和选项都“编码”为“字符串”,所以 ls 程序无法通过解码来辨别它们的到底是文件名还是选项 —— 此字符串非彼字符串也!
如果你使用过 Java 或者函数式语言(Haskell 或者 ML),你可能会了解一些类型理论(type theory)。在类型理论里,数据的类型是多样的,Integer, String, Boolean, List, record…… 程序之间传递的所谓“数据”,只不过就是这些类型的数据结构。然而按照 Unix 的设计,所有的类型都得被转化成 String 之后在程序间传递。这样带来一个问题:由于无结构的 String 没有足够的表达力来区分其它的数据类型,所以经常会出现歧义。相比之下,如果用 Haskell 来表示命令行参数,它应该是这样:
data Parameter = Option String | File String | ...
虽然两种东西的实质都是 String,但是 Haskell 会给它们加上“标签”以区分 Option 还是 File。这样当 ls 接收到参数列表的时候,它就从标签判断哪个是选项,哪个是参数,而不是通过字符串的内容来瞎猜。
文本流带来太多的问题
综上所述,文本流的问题在于,本来简单明了的信息,被编码成为文本流之后,就变得难以提取,甚至丢失。前面说的都是小问题,其实文本流的带来的严重问题很多,它甚至创造了整个的研究领域。文本流的思想影响了太多的设计。比如:
- 配置文件:几乎每一个都用不同的文本格式保存数据。想想吧:.bashrc, .Xdefaults, .screenrc, .fvwm, .emacs, .vimrc, /etc目录下那系列!这样用户需要了解太多的格式,然而它们并没有什么本质区别。为了整理好这些文件,花费了大量的人力物力。
- 程序文本:这个以后我会专门讲。程序被作为文本文件,所以我们才需要 parser。这导致了整个编译器领域花费大量人力物力研究 parsing。其实程序完全可以被作为 parse tree 直接存储,这样编译器可以直接读取 parse tree,不但节省编译时间,连 parser 都不用写。
- 数据库接口:程序与关系式数据库之间的交互使用含有 SQL 语句的字符串,由于字符串里的内容跟程序的类型之间并无关联,导致了这种程序非常难以调试。
- XML: 设计的初衷就是解决数据编码的问题,然而不幸的是,它自己都难 parse。它跟 SQL 类似,与程序里的类型关联性很差。程序里的类型名字即使跟 XML 里面的定义有所偏差,编译器也不会报错。Android 程序经常出现的 "force close",大部分时候是这个原因。与 XML 相关的一些东西,比如 XSLT, XQuery, XPath 等等,设计也非常糟糕。
- Web:JavaScript 经常被作为字符串插入到网页中。由于字符串可以被任意组合,这引起很多安全性问题。Web安全研究,有些就是解决这类问题的。
- IDE接口:很多编译器给编辑器和 IDE 提供的接口是基于文本的。编译器打印出出错的行号和信息,比如 "102:32 variable x undefined",然后由编辑器和 IDE 从文本里面去提取这些信息,跳转到相应的位置。一旦编译器改变打印格式,这些编辑器和 IDE 就得修改。
- log分析: 有些公司调试程序的时候打印出文本 log 信息,然后专门请人写程序分析这种 log,从里面提取有用的信息,非常费时费力。
- 测试:很多人写 unit test 的时候,喜欢把数据结构通过 toString 等函数转化成字符串之后,与一个标准的字符串进行比较,导致这些测试在字符串格式改变之后失效而必须修改。
还有很多的例子,你只需要在你的身边去发现。
什么是“人类可读”和“通用”接口?
当我提到文本流做接口的各种弊端时,经常有人会指出,虽然文本流不可靠又麻烦,但是它比其它接口更通用,因为它是唯一人类可读 (human-readable) 的格式,任何编辑器都可以直接看到文本流的内容,而其它格式都不是这样的。对于这一点我想说的是:
- 什么叫做“人类可读”?文本流真的就是那么的可读吗?几年前,普通的文本编辑器遇到中文的时候经常乱码,要折腾好一阵子才能让它们支持中文。幸好经过全世界的合作,我们现在有了 Unicode。
- 现在要阅读 Unicode 的文件,你不但要有支持 Unicode 的编辑器/浏览器,你还得有能显示相应码段的字体。文本流达到“人类可读”真的不费力气?
- 除了文本流,其实还有很多人类可读的格式,比如 JPEG。它可比文本流“可读”和“通用”多了,连字体都用不着。
所以,文本流的根本就不是“人类可读”和“通用”的关键。真正的关键在于“标准化”。如果其它的数据类型被标准化,那么我们可以在任何编辑器,浏览器,终端里加入对它们的支持,完全达到人类和机器都可轻松读取,就像我们今天读取文本和 JPEG 一样。
解决方案
其实有一个简单的方式可以一劳永逸的解决所有这些问题:
- 保留数据类型本来的结构。不用文本流来表示除文本以外的数据。
- 用一个开放的,标准化的,可扩展的方式来表示所有数据类型。
- 程序之间的数据传递和存储,就像程序内部的数据结构一样。
Unix 命令行的本质
虽然文本流引起了这么多问题,但是 Unix 还是不会消亡,因为毕竟有这么多的上层应用已经依赖于它,它几乎是整个 Internet 的顶梁柱。所以这篇文章对于当前状况的一个实际意义,也许是可以帮助人们迅速的理解 Unix 的命令行机制,并且鼓励程序员在新的应用中使用结构化的数据。
Unix 命令虽然过于复杂而且功能冗余,但是如果你看透了它们的本质,就能轻而易举的学会它们的使用方法。简而言之,你可以用普通的编程思想来解释所有的 Unix 命令:
- 函数:每一个 Unix 程序本质上是一个函数 (main)。
- 参数:命令行参数就是这个函数的参数。 所有的参数对于 C 语言来说都是字符串,但是经过 parse,它们可能有几种不同的类型:
- 变量名:实际上文件名就是程序中的变量名,就像 x, y。而文件的本质就是程序里的一个对象。
- 字符串:这是真正的程序中的字符串,就像 "hello world"。
- keyword argument: 选项本质上就是“keyword argument”(kwarg),类似 Python 或者 Common Lisp 里面那个对应的东西,短选项(看起来像 "-l", "-c" 等等),本质上就是 bool 类型的 kwarg。比如 "ls -l" 以 Python 的语法就是 ls(l=true)。长选项本质就是 string 类型的 kwarg。比如 "ls --color=auto" 以 Python 的语法就是 ls(color=auto)。
- 返回值:由于 main 函数只能返回整数类型(int),我们只好把其它类型 (string, list, record, ...) 的返回值序列化为文本流,然后通过文件送给另一个程序。这里“文件”通指磁盘文件,管道等等。它们是文本流通过的信道。我已经提到过,文件的本质是程序里的一个对象。
- 组合:所谓“管道”,不过是一种简单的函数组合(composition)。比如 "A x | B",用函数来表示就是 "B(A(x))"。 但是注意,这里的计算过程,本质上是 lazy evaluation (类似 Haskell)。当 B “需要”数据的时候,A 才会读取更大部分的 x,并且计算出结果送给 B。并不是所有函数组合都可以用管道表示,比如,如何用管道表示 "C(B(x), A(y))"?所以函数组合是更加通用的机制。
- 分支:如果需要把返回值送到两个不同的程序,你需要使用 tee。这相当于在程序里把结果存到一个临时变量,然后使用它两次。
- 控制流:main 函数的返回值(int型)被 shell 用来作为控制流。shell 可以根据 main 函数返回值来中断或者继续运行一个脚本。这就像 Java 的 exception。
- shell: 各种 shell 语言的本质都是用来连接这些 main 函数的语言,而 shell 的本质其实是一个 REPL (read-eval-print-loop,类似 Lisp)。用程序语言的观点,shell 语言完全是多余的东西,我们其实可以在 REPL 里用跟应用程序一样的程序语言。Lisp 系统就是这样做的。
数据直接存储带来的可能性
由于存储的是结构化的数据,任何支持这种格式的工具都可以让用户直接操作这个数据结构。这会带来意想不到的好处。
- 因为命令行操作的是结构化的参数,系统可以非常智能的按类型补全命令,让你完全不可能输入语法错误的命令。
- 可以直接在命令行里插入显示图片之类的 "meta data"。
- Drag&Drop 桌面上的对象到命令行里,然后执行。
- 因为代码是以 parse tree 结构存储的,IDE 会很容易的扩展到支持所有的程序语言。
- 你可以在看 email 的时候对其中的代码段进行 IDE 似的结构化编辑,甚至编译和执行。
- 结构化的版本控制和程序比较(diff)。(参考我的talk)
还有很多很多,仅限于我们的想象力。
程序语言,操作系统,数据库三位一体
如果 main 函数可以接受多种类型的参数,并且可以有 keyword argument,它能返回一个或多个不同类型的对象作为返回值,而且如果这些对象可以被自动存储到一种特殊的“数据库”里,那么 shell,管道,命令行选项,甚至连文件系统都没有必要存在。我们甚至可以说,“操作系统”这个概念变得“透明”。因为这样一来,操作系统的本质不过是某种程序语言的“运行时系统”(runtime system)。这有点像 JVM 之于 Java。其实从本质上讲,Unix 就是 C 语言的运行时系统。
如果我们再进一步,把与数据库的连接做成透明的,即用同一种程序语言来“隐性”(implicit)的访问数据库,而不是像 SQL 之类的专用数据库语言,那么“数据库”这个概念也变得透明了。我们得到的会是一个非常简单,统一,方便,而且强大的系统。这个系统里面只有一种程序语言,程序员直接编写高级语言程序,用同样的语言从命令行执行它们,而且不用担心数据放在什么地方。这样可以大大的减小程序员工作的复杂度,让他们专注于问题本身,而不是系统的内部结构。
实际上,类似这样的系统在历史上早已存在过 (Lisp Machine, System/38, Oberon),而且收到了不错的效果。但是由于某些原因(历史的,经济的,政治的,技术的),它们都消亡了。但是不得不说它们的这种方式比 Unix 现有的方式优秀,所以何不学过来?我相信,随着程序语言和编译器技术发展,它们的这种简单而统一的设计理念,有一天会改变这个世界。
59 3 标签: Unix软件设计阅读排行
-
![[从架构到设计]第二回:对象的旅行---对象和人,两个世界,一样](http://p1.codesocang.com/uploads/allimg/c130506/13CR23952ZF-1B554_lit.jpg)
[从架构到设计]第二回:对象的旅行---对象和人,两个世界,一样
2013-05-06
-
2015-12-03
-
2013-05-06
-

2013-05-06
-
2013-05-06
-
2015-03-09
-
2015-12-03
-
2013-05-06
最新文章
-

直播源码的崛起的巅峰:布谷一对一视频直播的蓬勃发展让您见证了
2019-08-02
-

2015-12-03
-
2015-12-03
-
2015-12-03
-

2015-12-03
-
2015-12-03
-
2015-12-03
-
2015-12-03
热门源码
